

































Description
Code for the paper: Juneja, V., Dinkar, S. K., & Gupta, D. V. (2022). An anomalous co‐operative trust & PG‐DRL based vampire attack detection & routing. Concurrency and Computation: Practice and Experience, 34(3), e6557.
Disclaimer: Results Images are subject to copyright of the paper itself.
Introduction
Wireless Sensor Networks (WSN) have become an essential part of the modern, smart, and technological world. These include areas like smart cities, industrial automation, agriculture, healthcare, etc. These networks consist of small sensor nodes that transfer information by communicating with each other.
However, malicious attacks can threaten these nodes, damaging the network structure and increasing energy consumption for data transfer. Vampire Attack is a type of this attack, which drains the battery of the nodes by making the data travel longer routes.
Here a PG-DRL (Policy Gradient Deep Reinforcement Learning) is proposed for vampire attack detection, and mitigation by rerouting the sensor node transfer path to avoid malicious nodes. Fig.1 depicts a category of Vampire attack called Carousel attack. It can be seen from the figure that the frequency of node hops increases significantly when WSN is under attack.
Problem Statement
To identify these malicious attacks trust thresholds are used by the traditional methods which typically lack in effectiveness because these threshold values vary for each different network and require manual tuning based on knowledge. Furthermore, safe routing in WSNs usually demands the whole route to be shared across nodes, therefore increasing the danger of route manipulation by malicious nodes and hence wasting more energy.
Contributions
- Novel Approach of Detection for Vampire Attacks:
- Since vampire attacks quickly deplete the energy of sensor nodes in a network, they are very damaging.
- The authors devised a novel approach using cooperative trust values and spectral clustering that finds and separates hostile nodes, hence enhancing network security and performance.
- Routing Energy-Efficiently to Reduce Vampire Attacks:
- A reinforcement learning-based routing algorithm is developed that chooses the next hop for data transfer in real time to stop vampire attacks.
- This concept guarantees the network stays efficient even when under attack by using the minimum of energy for data transfer. Effective across numerous network situations, the model is versatile, can adapt to changes, and does not need specified paths.
Methodology
The methodology involves four steps which are,
- Calculating cooperative trust scores to identify reliable nodes for data transmission: In this paper, each sensor node has one-to-many connections in the network and a cooperative trust score is calculated based on the energy levels of its neighboring nodes. The eigenvalues of the cooperative trust matrix open the door to identifying the malicious vampire nodes.
- Detecting the malicious vampire nodes by Gaussian Mixture Model (GMM): Using relative eigenvalues of the cooperative trust matrix, a GMM model with Expectation- maximization (EM) clustering is used to cluster the nodes into benign and attack categories.
- Training of the PG-DRL model:
- Policy Gradient Deep Reinforcement Learning (PG-DRL) is an advanced method that enables a system to learn how to make decisions by continuously improving its strategy through trial and error. PG-DRL trains an agent to maximize rewards by avoiding vampire nodes. The algorithm involves initializing the actor-critic method where the critic network optimizes the action or state value while the actor network works on the update policy parameters guided by the critic network. This results in a final greater cumulative reward i.e., the best tuning parameters.
- The PG-DRL algorithm is implemented with specific parameters and tested over multiple episodes to ensure the agent learns to avoid vampire nodes and select energy-efficient routes.
- And a rerouting model based on the PG policy:
The rerouting process for the efficient node route selection in WSN after detecting the Vampire nodes is:
- If the system (agent) selects a good next node that isn’t a vampire node and still has energy left, it earns a reward. This reward is calculated based on how much energy the chosen node has and how far away it is. The closer the node and the more energy it has, the better the reward.
- If the system accidentally chooses a vampire node, it gets a big penalty of -100. This is to discourage it from making that mistake again.
- If the system reaches a point where it can’t make any more moves, either because there’s no energy left or no new nodes to select, it gets a small penalty of -1.
Implementation discussion with code snippets
First, the trust score calculation is done with the help of energy consumption and distribution in the network.
conn = nodes{1}.inrange;
E_temp=zeros(size(conn)); E_temp_norm = zeros(size(conn));
for rr=1:size(conn,1)
distt=[];temp=[];Ee=[];
distt=nodes{1}.distance(1,find(conn(rr,:)));
for ii=1:numel(find(conn(rr,:)))
Ee(ii)=(alpha1*datarate(ff)*pktsize*8)+(alpha2*datarate(ff)*pktsize*8)*(distt(ii))^alpha;
end
E_temp(rr,find(conn(rr,:))) = E(find(conn(rr,:)));
E_temp(rr,find(conn(rr,:))) = E(find(conn(rr,:)))-Ee;
E_temp_norm(rr,:) = E_temp(rr,:)./sum(E_temp(rr,:));
E_temp_norm(rr,E_temp_norm(rr,:)<0)=0;
end
A=conn;
W = sum(A,3);
W(isnan(W)) = 0;
W = W.*(E_temp_norm);
[vec,val] = eig(W);
endconnis a matrix indicating which nodes are in the range of the first nodenodes{1}.- The trust score for each node is calculated based on the energy levels of its neighboring nodes. Specifically, the energy consumed during communication is subtracted from the initial energy of each neighbor, and these adjusted energy levels are normalized to reflect their relative trustworthiness.
- This normalized energy matrix
E_temp_normrepresents how the energy is distributed among the neighboring nodes, providing a measure of cooperative trust within the network. - The cooperative trust matrix
Wincorporates the normalized energy levels of neighboring nodes. - By performing eigenvalue decomposition on this trust matrix by
vecandval, eigenvalues and eigenvectors are derived to reveal the structural properties of the network. - Vampire nodes may cause disproportionate energy loss or irregular trust distributions, which lead to anomalies resulting in unusual eigenvalues. These anomalies are used to identify the malicious nodes.
Now, anomaly detection using GMM is carried out.
function clusterX = anomalyDetection(val)
tt = diag(val);
options = statset('MaxIter', 1000);
gmfit = fitgmdist(tt, 2, 'Options', options, 'Replicates', 5, 'CovarianceType', 'full');
clusterX = cluster(gmfit, tt);
clusterX(clusterX == 0) = 2;
end- From the above code, we can see that the diagonal of the matrix
valis extracted usingdiag(val). This typically represents the eigenvalues of the cooperative trust matrix. fitgmdist(tt, 2, ...)fits the GMM for the data (tt) with 2 components, corresponding to the two clusters (one for normal nodes and one for potential attacks).- The GMM fitting is done with
OptionsReplicatesandCovarianceTypeproviding greater flexibility in modeling the data distribution. Clusteringcluster(gmfit, tt)is based on the highest posterior probability, which helps in identifying nodes that deviate from normal behavior, such as potential Vampire nodes.clusterXis the result that contains cluster labels for each node input.
The reinforcement learning model PG-DRL is created and trained with the code given below
function [trainingStats,experience] = createDQN1(nbrs,dst,crntNode,nodes,rtngtble,resE,VampireNid,dirname)
simT= vanet simulation tiime
vhclN = vehcile number
create DQN agent
env = MyWSNEnvironment1(nbrs,dst,crntNode,nodes,rtngtble,resE,VampireNid);
obsInfo = getObservationInfo(env);
numObservations = obsInfo.Dimension(1);
actInfo = getActionInfo(env);
L=200;
numDiscreteAct = numel(actInfo.Elements);
actorNetwork = [
imageInputLayer([numObservations 1 1],'Normalization','none','Name','state')
reluLayer('Name','CriticStaterelu3')
fullyConnectedLayer(numDiscreteAct,'Name','FC4')
softmaxLayer('Name','actionProb')
];
actorOpts = rlRepresentationOptions('LearnRate',1e-2,'GradientThreshold',1);
actor = rlStochasticActorRepresentation(actorNetwork,obsInfo,actInfo,'Observation',{'state'},actorOpts);
agent = rlPGAgent(actor);
trainOpts = rlTrainingOptions(...
'MaxEpisodes', 500, ...
'verbose',true,...
'Plots','training-progress',...
'StopTrainingCriteria','AverageReward',...
'ScoreAveragingWindowLength',100,...
'SaveAgentDirectory', pwd + "/"+dirname);
trainingStats = train(agent,env,trainOpts);
save(trainOpts.SaveAgentDirectory + "/finalAgent.mat",'agent')
simOptions = rlSimulationOptions('MaxSteps',500);
experience = sim(env,agent,simOptions);nbrs,dst,crntNode,VampireNid,dirnameetc are the function inputs for the model. TheMyWSNEnvironment1function creates the WSN environment using the provided input parameters.- An actor-critic network is created to represent the agent’s policy, determining actions based on the current state. The network includes an input layer for state observations, a
reluLayer, afullyConnectedLayerfor mapping to actions, and asoftmaxLayerfor generating action probabilities in a stochastic policy. - The actor is configured with options like learning rate and gradient threshold and is created using
rlStochasticActorRepresentation. The agent, defined as arlPGAgent(Policy Gradient Agent), optimizes the policy directly through reinforcement learning. - After that training options for the agent are set up. The agent is trained and saves the final model, then simulates the agent’s performance in the environment, storing the results for further analysis.
Finally, the rerouting path based on the PG policy is implemented. This code is used for selecting the next neighbor:
% Get action
nxtNbr = getForce(this, Action);
% Calculate the residual energy
[E,~,~,~,~] = evaluation(this.nodes.distance(this.crntNode, nxtNbr), 1);
rsE = this.resE;
rsE(nxtNbr) = this.resE(nxtNbr) - E;
% Update system states
this.State = nxtNbr;
% Check terminal condition
IsDone = rsE(nxtNbr) == 0 || ismember(nxtNbr, this.rtngtble) ...
|| this.nodes.distance(this.crntNode, nxtNbr) > 30;
this.IsDone = IsDone;
-
nxtNbris used to decide what packet should be routed to based on the actionActionchosen by the PG-DRL agent. -
Ecomputes the energy needed to send the packet from the current node to the next nodenxtNbrbased on their distance. The residual energy of the selected node is then updated by subtracting this energy from its current value viarsE(nxtNbr). -
The updated node is then saved as the current using
this.state=nxtNbr -
Finally the
IsDonefunction checks whether the current routing episode should terminate. The reinforcement reward function is given byfunction Reward = getReward(this,nxtNbr) if ~this.IsDone && (~ismember(nxtNbr,this.VampireNid)) Reward = (this.resE(nxtNbr)/this.nodes.distance(this.crntNode,nxtNbr)^2); elseif ~this.IsDone && (ismember(nxtNbr,this.VampireNid)) Reward=-100; else Reward = -1; end end -
The
Rewardfunction trains the PG-DRL agent by giving it a positive reward for the correct routing path and reinforces this behavior. And heavily penalizes if the model selects the Vampire nodethis.VampireNid.Results
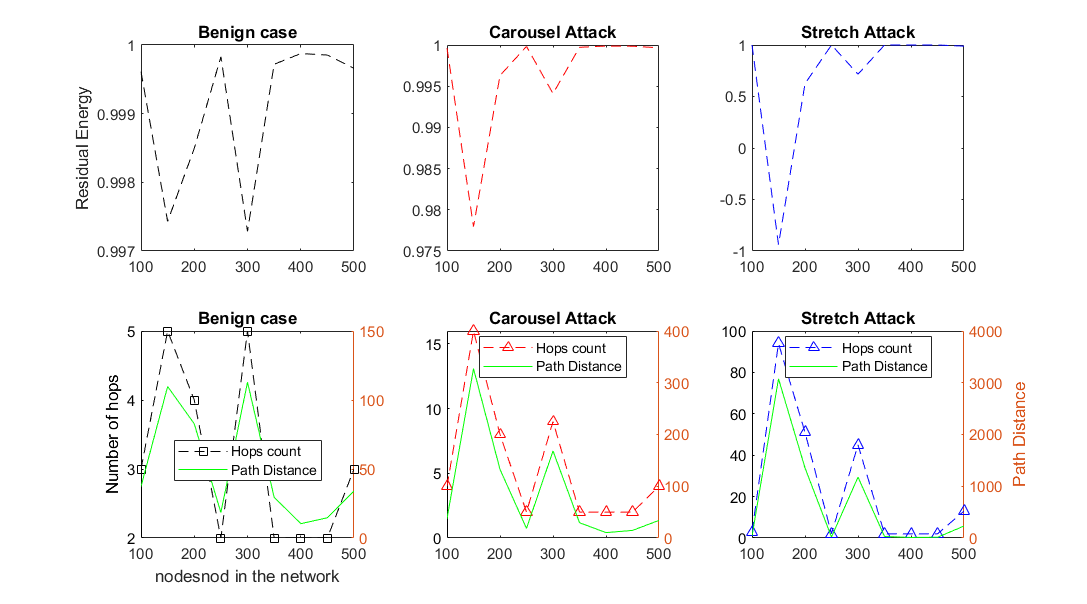
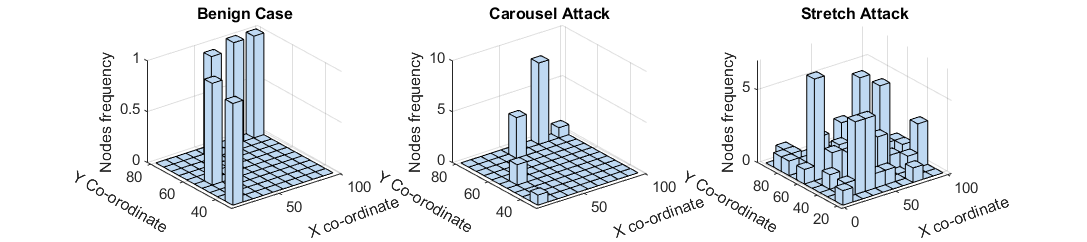
A WSN environment with a predefined number of nodes is established, using Dynamic Source Routing (DSR) as the baseline protocol. As it is explained in the methodology the vampire nodes are detected by the energy consumption of these malicious nodes compared to benign nodes. The figure below shows energy consumption of the two types of vampire nodes: Carousel and Stretch attacks.
-
It can be seen from the figure that stretch attacks consume more energy due to higher hop counts.
-
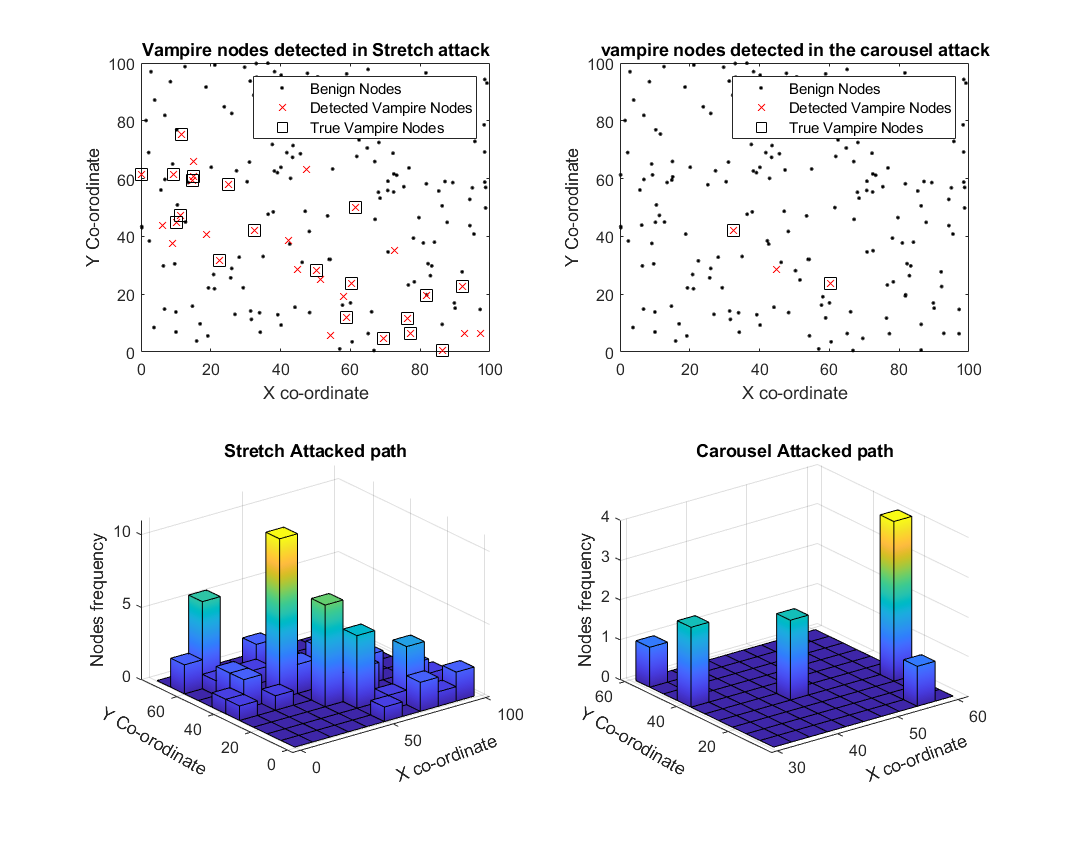
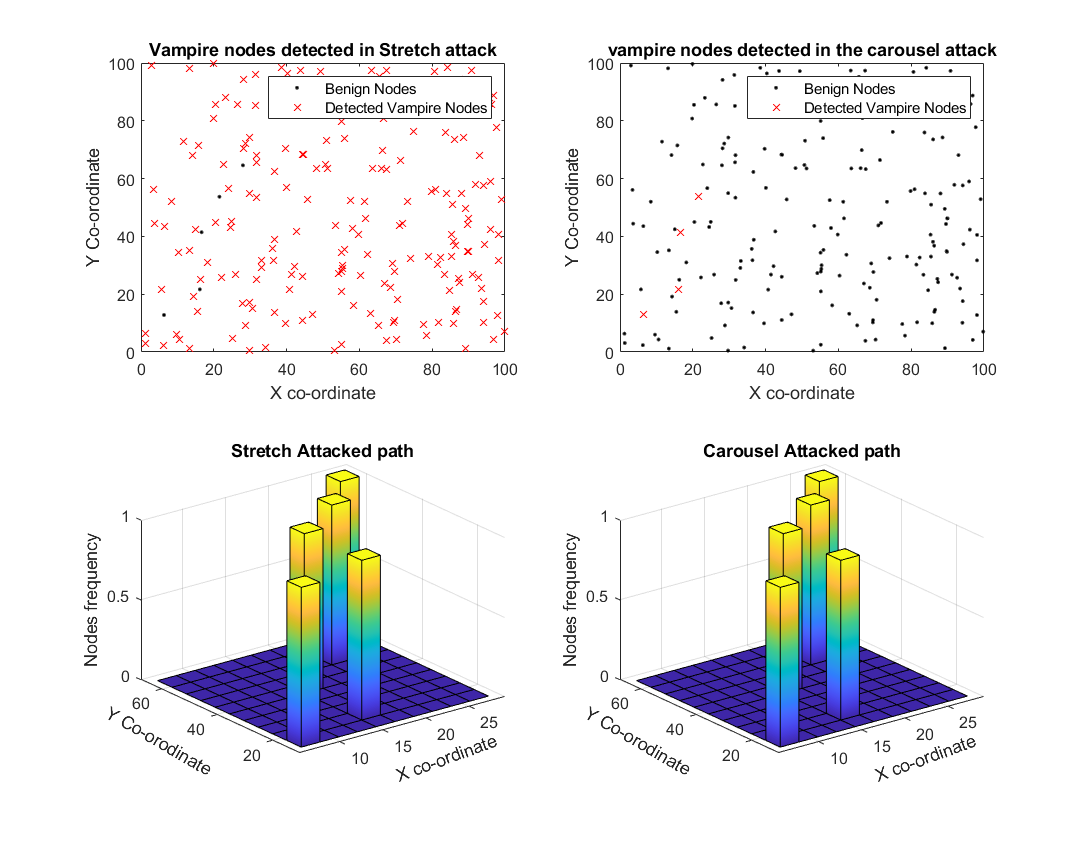
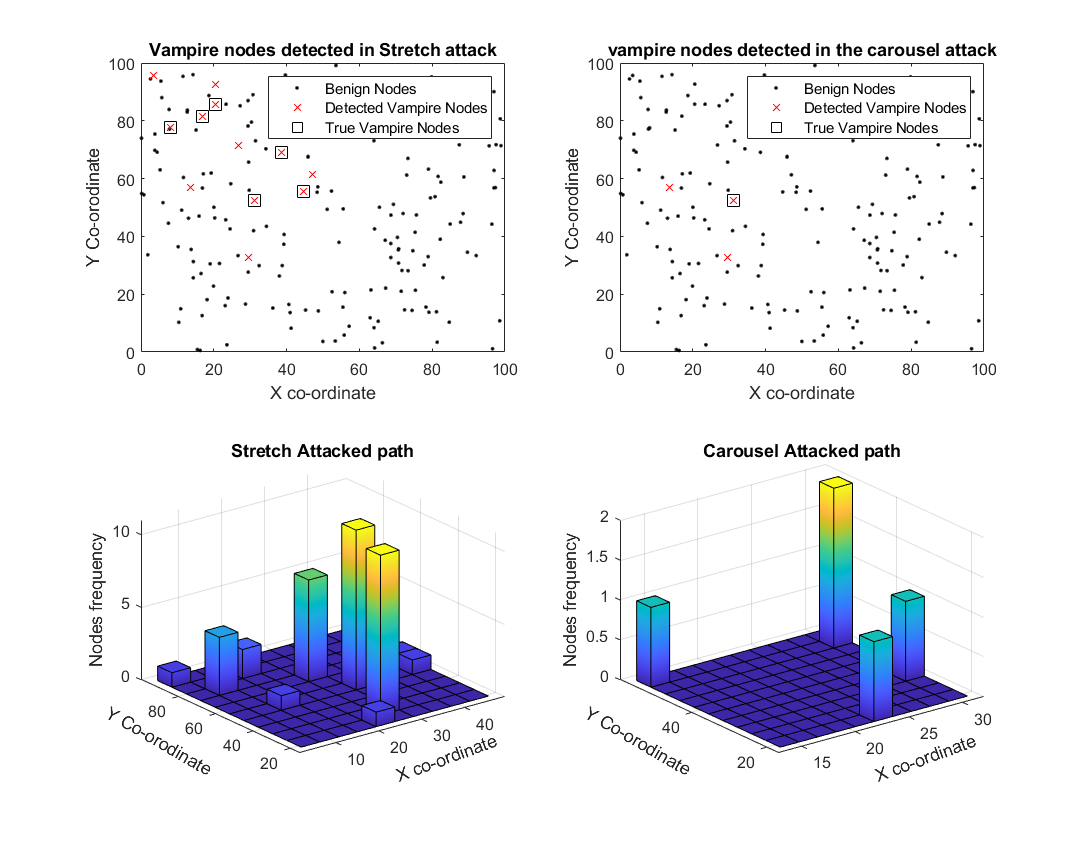
The current algorithm is evaluated in a simulated WSN scenario with 80% vampire nodes in the network. The figure below shows the detected vampire nodes and true vampire nodes labeled in the DSR path for both carousel and stretch attacks.
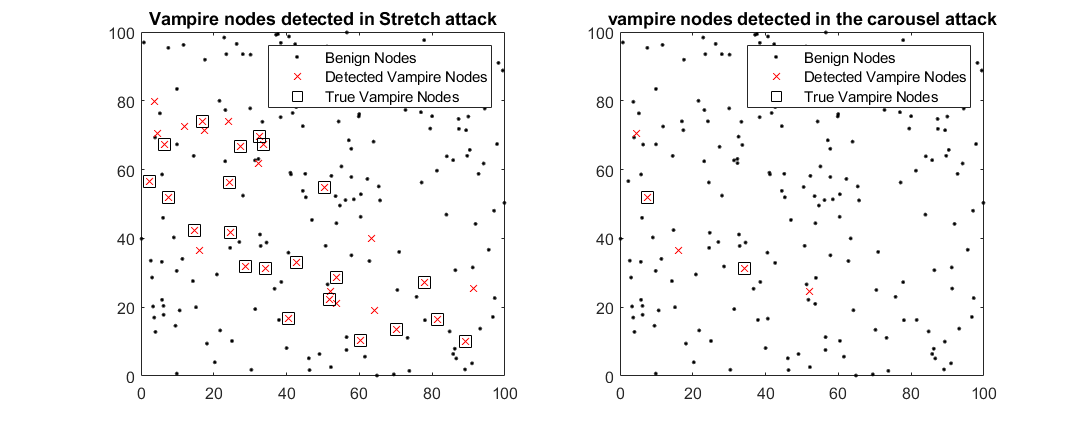
-
The proposed detection algorithm demonstrated 100% accuracy in detecting vampire nodes under stretch and carousel attacks in some trials, though this accuracy decreases with higher densities of vampire nodes.
-
The statistical analysis shows that detection accuracy remains high, especially in networks with fewer vampire nodes.
-
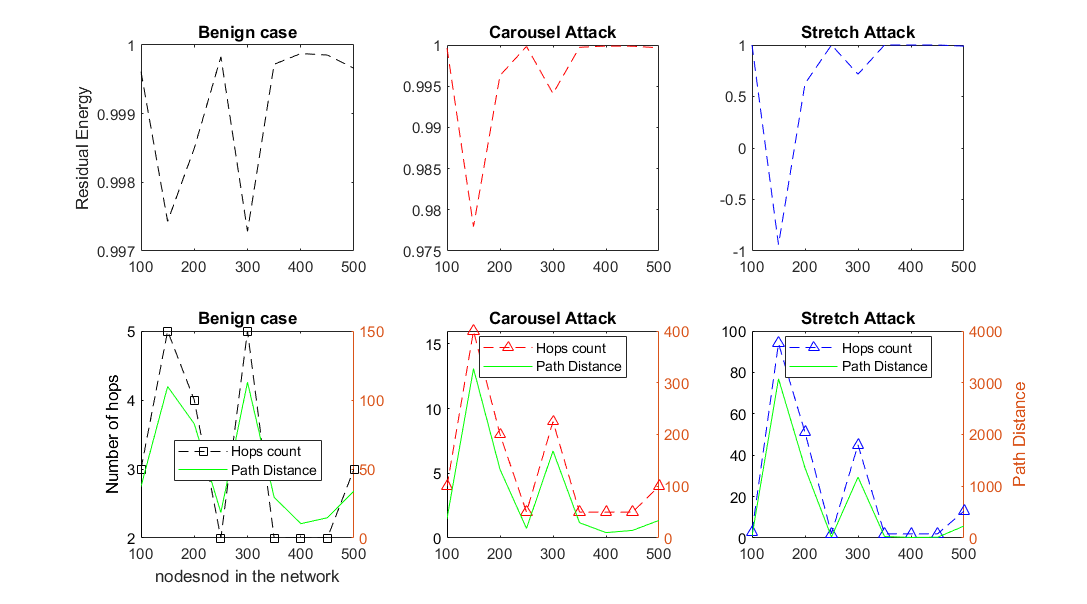
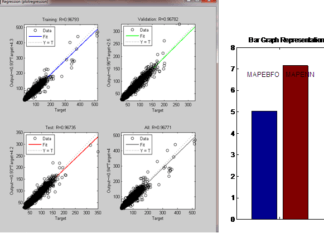
After the detection of these vampire nodes, it is necessary to find a secure route for data transfer among the nodes with the least energy consumption. The PG-DRL algorithm is used to secure routing. The training results show that the PG-DRL algorithm effectively learns to avoid vampire nodes over time, improving the network’s average reward and ensuring secure routing.
-
The PG-DRL routing is compared to DSR routing under both benign and attack scenarios, the figure below shows that PG-DRL can reduce the number of hops and energy consumption under attack conditions. The network lifetime is also improved by approximately 3% when using PG-DRL compared to DSR.
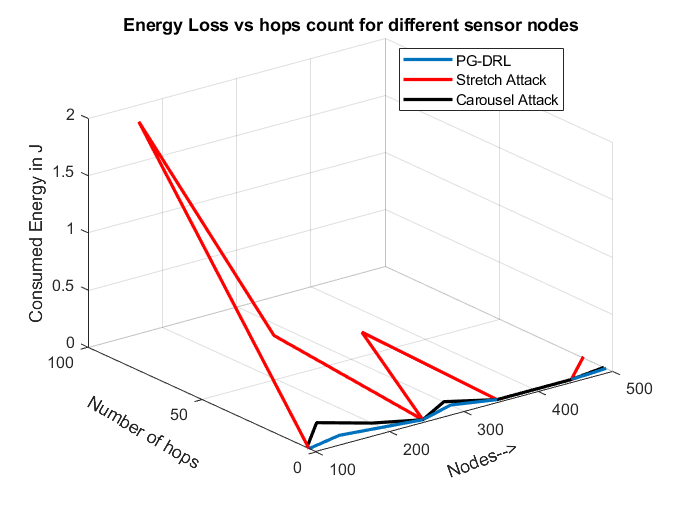
-
The proposed detection algorithm outperforms existing methods like Theil Index and fuzzy trust score-based approaches, with higher detection accuracy even under high vampire node densities. The PG-DRL algorithm provides secure and efficient routing, leading to an increased network lifetime.
Conclusion
The proposed two-fold approach combining cooperative trust calculation and PG-DRL for vampire attack detection and node path rerouting shows significant improvements in attack detection accuracy and creating the shortest and most secure routing to avoid the detected Vampire nodes.
By avoiding routes with Vampire nodes and selecting paths that use the least amount of energy, the proposed approach reduces energy consumption. This results in increased operational time of the nodes and increased network lifetime.
References
- Juneja, V., Dinkar, S. K., & Gupta, D. V. (2022). An anomalous co‐operative trust & PG‐DRL based vampire attack detection & routing. Concurrency and Computation: Practice and Experience, 34(3), e6557.
- Pu, Cong, Jacqueline Brown, and Logan Carpenter. “A Theil Index-Based Countermeasure Against Advanced Vampire Attack in Internet of Things.” In 2020 IEEE 21st International Conference on High Performance Switching and Routing (HPSR), pp. 1-6. IEEE, 2020.
- Srikaanth, P. Balaji, and V. Nagarajan. “A Fuzzy Trust Relationship Perspective-Based Prevention Mechanism for Vampire Attack in MANETs.” Wireless Personal Communications 101, no. 1 (2018): 339357.
- Isaac Sajan, R., and J. Jasper. “Trust‐based secure routing and the prevention of vampire attack in wireless ad hoc sensor network.” International Journal of Communication Systems 33, no. 8 (2020): e4341.
- Srikaanth, P. Balaji, and V. Nagarajan. “Semi-Markov chain-based grey prediction-based mitigation scheme for vampire attacks in MANETs.” Cluster Computing 22, no. 6 (2019): 15541-15549.

abhishek gupta
ScholarsColab.com is an innovative and first of its kind platform created by Vidhilekha Soft Solutions Pvt Ltd, a Startup recognized by the Department For Promotion Of Industry And Internal Trade, Ministry of Commerce and Industry, Government of India recognised innovative research startup.

Reviews
There are no reviews yet.